Learned data structures use machine learning techniques to improve the performance of queries. Traditional data structures, such as B-trees and hash tables, are designed to work well for a wide variety of data distributions. However, learned data structures can be tailored to the specific data distribution of a given dataset, which can lead to significant performance improvements.
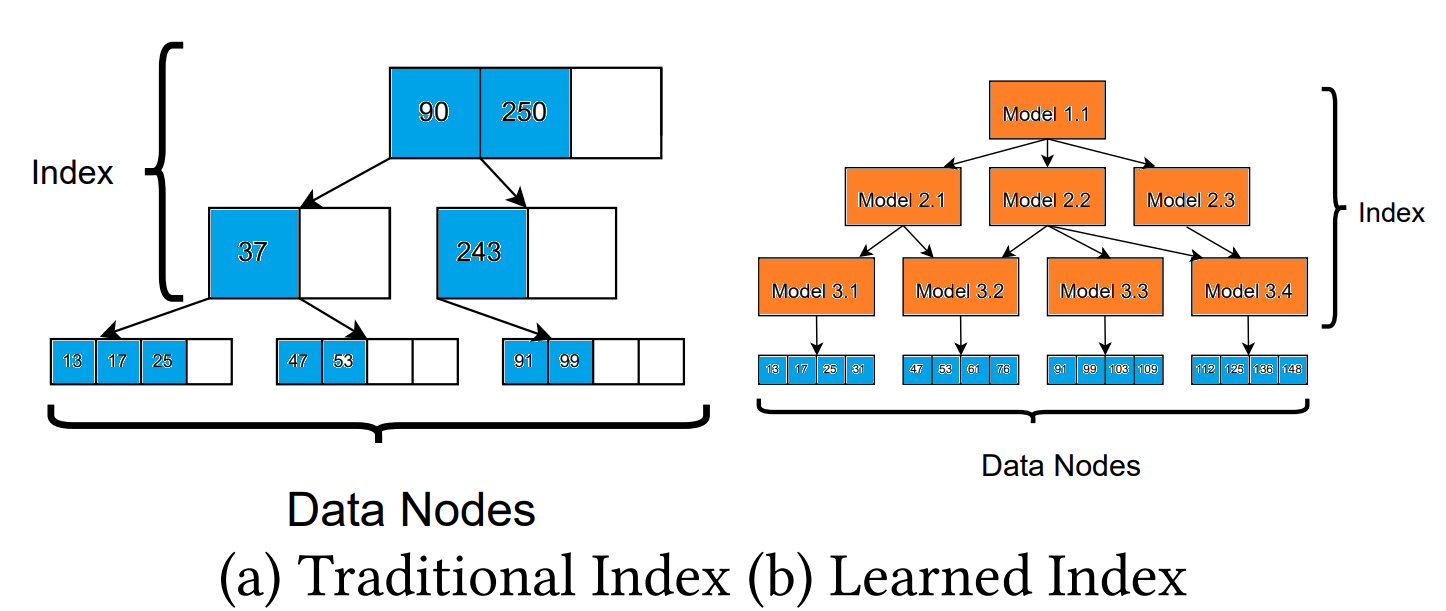
Learned data structures typically work by learning a model of the cumulative distribution function (CDF) of the data keys. The CDF of a dataset is a function that maps each key to its relative position in the dataset. Once the CDF has been learned, it can be used to quickly and accurately locate the position of any key in the dataset.
There are a variety of different machine learning techniques that can be used to learn the CDF of a dataset. One common approach is to use a neural network. Neural networks are able to learn complex relationships between data points, and they can be used to learn the CDF of a dataset even if the data distribution is highly skewed or non-uniform.
Another approach to learning the CDF of a dataset is to use a simpler machine learning technique, such as linear regression. Linear regression models can be used to learn a linear approximation of the CDF function. This approach is often less accurate than using a neural network, but it is also much faster and more efficient.
Once the CDF of the data keys has been learned, it can be used to implement a variety of different data structures. For example, one simple approach is to use the CDF to create a lookup table. The lookup table would map each key to its relative position in the dataset. To locate the position of a key, the database engine would simply look up the key in the lookup table.
Another approach is to use the CDF to construct a more complex data structure, such as a neural network data. Neural network dataes are able to learn complex relationships between data keys, and they can be used to implement a variety of different search algorithms.
Learned data structures are still under development, but they have the potential to significantly improve the performance of database queries. In some cases, learned data structures have been shown to outperform traditional data structures by up to 70%.
Here are some of the advantages of learned data structures:
- They can be tailored to the specific data distribution of a given dataset, which can lead to significant performance improvements.
- They are able to handle complex data distributions that are difficult or impossible to handle with traditional data structures.
- They can be used to implement a variety of different data structures, which gives database designers more flexibility to choose the right data structure for their specific needs.
Here are some of the challenges of learned data structures:
- They can be more complex to implement than traditional data structures.
- They can be slower to update than traditional data structures when the data changes.
- They can be more memory-intensive than traditional data structures.
Overall, learned data structures are a promising new technology with the potential to significantly improve the performance of database queries.